BM25¶
When we look at the plugins, we will see how BM25 comares with TF-IDF and also fine tuning parameters for BM25.
What is BM25?¶
BM25 (Best Matching 25th Iteration) an advancement on TF-IDF
Why is it better than TF-IDF?
- It has diminishing returns - Adding the 10th query term doesn't help as much as adding the 2nd "caquery term".
- It considers document length - Longer docs aren't automatically penalized.
- It has tuning knobs - You can adjust it for different use cases with
k1for key word saturation andbfor document length. (MySQL does not allow us to change the settings, but it is useful to know this as we may have a database that does do this, either instead of MySQL or as an additional content database)
The BM25 Formula¶
A helpful infographic:
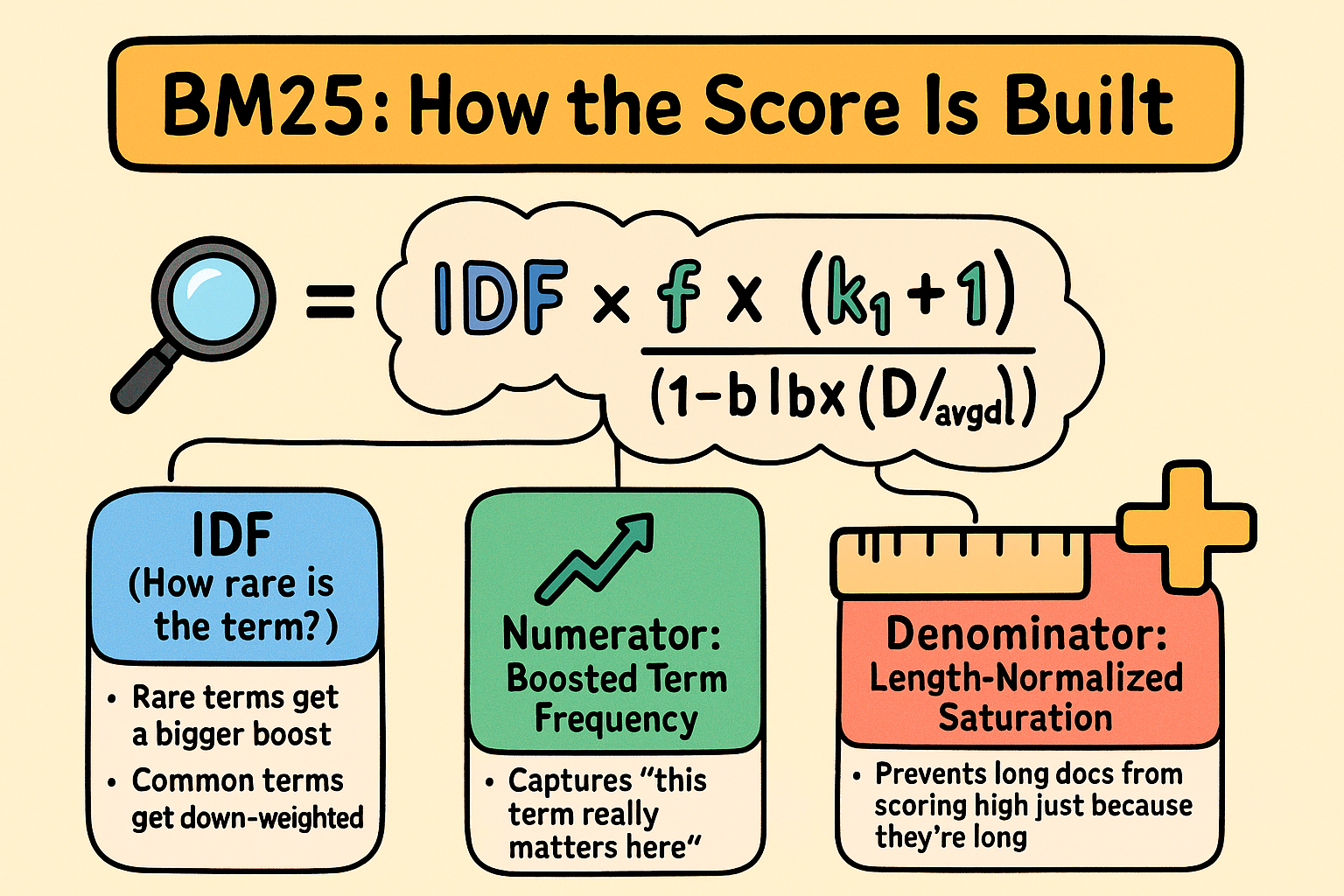
The Formula Breakdown¶
We don't need to go into detail as it is not necessary. The key takeaways are that k1, (term saturation) and b, (document length normalisation), are introduced to add parameters to fine tune BM25.
BM25(D, Q) = Σ IDF(qi) × (f(qi, D) × (k1 + 1)) / (f(qi, D) + k1 × (1 - b + b × |D| / avgdl))
Where:
- D = Document being scored
- Q = Query (search terms)
- qi = Each term in the query
- f(qi, D) = Frequency of term qi in document D
- |D| = Length of document D (word count)
- avgdl = Average document length in collection
- k1 = Term frequency saturation parameter (usually 1.2 to 2.0)
- b = Length normalization parameter (usually 0.75)
BM25 is a ranking formula that scores how well a document matches a search query.
The core idea: For each word in your query, BM25 calculates a score based on:
-
IDF (Inverse Document Frequency) - How rare/important the word is across all documents. Rare words get higher scores.
-
Term frequency with diminishing returns - How often the word appears in this document, but with a ceiling. The formula
(f × (k1 + 1)) / (f + k1)means the 1st occurrence matters a lot, the 10th occurrence barely matters. -
Length normalization - Longer documents get penalized (controlled by
b), because they naturally contain more words. The(1 - b + b × |D| / avgdl)part adjusts for document length.
Example: Searching "php tutorial"
- "php" appears in 1000 docs → low IDF
- "tutorial" appears in 100 docs → higher IDF
- A short doc with "tutorial" mentioned 3 times scores higher than a long doc with it mentioned 20 times
The final score is the sum of scores for each query term. Documents with the highest BM25 scores are ranked first.
Remember:
- IDF: How special is this word?
- Numerator: Boost the frequency (but not too much)
- Denominator: Normalize for document length and saturation
- Result: A score that balances everything perfectly!
Understanding the Parameters¶
Please note - MySQL does not let us change these parameters.
It can be of value to understand k1 and b as you may have a different database or have an additonal database for search that enables k1 and b fine tuning.
k1 (Term Frequency Saturation)¶
What k₁ does¶
The k₁ parameter controls how quickly the curve flattens:
- Lower k₁ → curve flattens sooner (more aggressive saturation meaning the threshold for 'term stuffing' to be considered is lower so the campening of more terms happens sooner).
- Higher k₁ → curve stays steeper longer (less saturation, closer to linear). More 'stuffing' is tolerated.
Here's a clear comparison showing how k1 affects BM25 scores as term frequency increases:
Setup: Same document (length=100), avgdl=100, N=1000 docs, df=50
Low k1 (0.5) - Quick saturation:
| Term Freq | BM25 Score | Score Increase |
|---|---|---|
| 1 | 2.18 | - |
| 2 | 2.62 | +0.44 |
| 5 | 3.27 | +0.65 |
| 10 | 3.60 | +0.33 |
| 20 | 3.82 | +0.22 |
| 50 | 3.99 | +0.17 |
| 100 | 4.07 | +0.08 |
Medium k1 (1.5) - Standard:
| Term Freq | BM25 Score | Score Increase |
|---|---|---|
| 1 | 2.72 | - |
| 2 | 3.63 | +0.91 |
| 5 | 4.90 | +1.27 |
| 10 | 5.81 | +0.91 |
| 20 | 6.53 | +0.72 |
| 50 | 7.17 | +0.64 |
| 100 | 7.53 | +0.36 |
High k1 (3.0) - Slow saturation:
| Term Freq | BM25 Score | Score Increase |
|---|---|---|
| 1 | 3.27 | - |
| 2 | 4.90 | +1.63 |
| 5 | 7.17 | +2.27 |
| 10 | 8.72 | +1.55 |
| 20 | 10.00 | +1.28 |
| 50 | 11.25 | +1.25 |
| 100 | 11.80 | +0.55 |
Lower values of k_1 in BM25 favor fewer repeated terms — they dampen the influence of term frequency more aggressively.
Here's why:
BM25 uses a saturation function for term frequency:
Low k_1 (e.g., 0.2):
- The score increases rapidly at first but flattens quickly.
- Additional occurrences of a term contribute very little.
- This favors documents where a term appears once or twice.
High k_1 (e.g., 2.0):
- The score increases more gradually and saturates later.
- Repeated terms continue to add value longer.
- This favors documents with many occurrences of the same term.
*So, a lower k_1 favors less repetition — it rewards term presence but penalizes term frequency more heavily. *
Key Observations:
- Low k1: Scores plateau quickly (3.27→4.07 from tf=5 to tf=100)
- High k1: Scores keep growing (7.17→11.80 from tf=5 to tf=100)
- Lower k1 = less reward for repeated terms (good for spam prevention)
- Higher k1 = more reward for repeated terms (good when repetition matters)
Why this matters - "Eliteness"¶
Once a term appears several times in a document, that document is already "elite" (highly relevant) for that topic. Seeing the term 50 more times doesn't make it 50 times more relevant—it just confirms what you already know.
For example, if you search for "php" and a document mentions it 5 times versus 500 times in another, the second document isn't necessarily 100x better. BM25's saturation prevents over-rewarding documents that spam keywords.
Default: 1.2-2.0
b (Length Normalization)¶
Default: 0.75
Controls how much document length affects the score.
b = 0: Document length doesn't matter at all
b = 0.5: Document length matters somewhat
b = 0.75: Document length matters a good amount (default)
b = 1.0: Document length matters completely - long documents are penalised
For a given number of terms, if b=1 then shorter documents get a higher score relative to a larger document. Remember, it is relative scores not absolute values.
We will see examples of this in the plugins which will make it visually more inromative.
Can b > 1?¶
Yes, b in BM25 can technically be greater than 1, though it's unusual and not recommended in practice.
The parameter b controls document length normalization in BM25:
- b = 0: no length normalization (document length is ignored)
- b = 1: full linear normalization (standard setting)
- b > 1: over-normalization (penalizes longer documents more heavily)
What happens when b > 1:
When b > 1, you're applying a stronger penalty to longer documents than the standard normalization. The length normalization term becomes:
For a document longer than average (doc_length > avg_doc_length), values of b > 1 will make this denominator larger, further reducing the score.
Why it's not standard:
The typical range is b ∈ [0, 1] because:
- BM25 was empirically tuned with
b ≈ 0.75as optimal for most collections - Values > 1 can over-penalize longer documents that are legitimately relevant
- The theoretical justification for BM25's length normalization assumes
b ≤ 1
When you might consider b > 1:
- Your collection has verbose/padded documents that aren't proportionally more informative
- You want to strongly favor concise, focused documents
- You're dealing with spam or artificially inflated content
If you're experimenting with this, I'd suggest testing values like 1.1 or 1.2 first and evaluating against your specific use case, rather than jumping to much higher values.
Higher b = Longer docs penalized more
Lower b = Longer docs penalized less
Tuning Parameters for Different Use Cases¶
Unfortunately, MySQL does not enable k1 and b tuning for our WordPress sites. If it did then...
Higher k1 (e.g., k1 = 2.0):¶
Use when:
- Longer documents are common
- Term frequency is very important
- E-commerce product descriptions
- Technical documentation
Effect: More emphasis on how often terms appear
Lower k1 (e.g., k1 = 1.0):¶
Use when:
- Short documents (tweets, titles)
- Presence matters more than frequency
- News headlines
Effect: Less emphasis on repetition
Higher b (e.g., b = 1.0):¶
Use when:
- Document lengths vary widely
- Shorter docs should be favored
- Blog posts vs. books
Effect: Strong length normalization
Lower b (e.g., b = 0.5):¶
Use when:
- All documents are similar length
- Length shouldn't matter much
- Academic papers (all ~8 pages)
Effect: Weak length normalization
Key Takeaways¶
BM25 is smarter than TF-IDF because:
-
Diminishing Returns
-
The 2nd occurrence helps a lot
- The 100th occurrence barely helps
-
Prevents keyword stuffing naturally
-
Length Normalization
-
Short, focused docs get a bonus
- Long, rambling docs get penalized
-
Adjustable with parameter b
-
Tunable
-
k1 controls term frequency importance
- b controls length normalization
-
Customize for your use case!
-
More Realistic
-
Mimics human relevance judgments
- Used by Elasticsearch, Lucene, Solr
- Industry standard for good reason!